
You see what data can bring to your organisation. And you probably have tasted success in your first data-related projects. But be cautious – you may just be entering a slowdown phase. Why’s that? And above all, how can you avoid the slowdown? How do you ensure that your data story continues to grow in a scalable way? Let us introduce you to our soup factory metaphor.
Don’t be a one-hit wonder
As a CxO or other decision-maker in a company large or small, you value data. You know that data-driven operations are increasingly important for competitiveness and efficiency, and you see the benefit of investing in it. As such, you may have built your first innovative AI use case or you have scored with new management dashboards. And yet, it is precisely at this point that the engine often starts sputtering.
It’s all about the “why”
Your first AI pilot or first company dashboard is often a quick win. But building the appropriate infrastructure for the structural and scalable data use is a much bigger challenge in terms of complexity, lead time and budget. At that point, the required budget then demands a good high-level understanding of the “what” and the “why” of investing in stronger Data Foundations.
After the initial successes, pain points often emerge. You may recognize your story in one of the following:
- Difficulties to link data from different platforms to get a complete picture of business performance.
- Inconsistent data processing in different pockets of the organisation leads to inconsistent findings.
- Manual processes lead to errors, resulting in frequent unavailability of important business information and poor data quality.
The soup metaphor continues
In 2015, we wrote a small analogy between building algorithms and preparing soup. Since then, the article has helped us convey the crucial building concepts of algorithms to decision makers.
That helped us then. But, what if you had to serve thousands of customers a day? What if you had to cook a variety of soups, such as Consommé, Shark Fin Soup or Pho? And what if some customers prefer a single luxurious portion, while others want plain 5-litre buckets? Well, this is where the role of Data Foundations comes in.
In this short article, we will introduce the soup factory as a metaphor for building the required data foundations to make and serve soup in an automated, structured and scalable way.
The soup factory
Simply put, a soup factory is designed to collect raw ingredients and transform them into delicious soups through a highly optimal sequence of steps. The factory is built to achieve certain goals, including efficiency, consistency and integrity.
Efficiency means achieving high throughput by ensuring that the raw materials flow easily from station to station without a hitch, and that the inputs and outputs of the intermediate processes are matched. In that process, the quality of the soup must be consistent so that customers can be confident that they are getting value for money. Finally, the products we deliver must be of high integrity, because the last thing we need is for our customers to get food poisoning.
Likewise, a data warehouse, one of the many concepts in Data Foundations, resembles the soup factory insofar as it also transforms raw materials (data in this case) into meaningful, understandable and easily accessible information. With some abstraction, we consider three main steps in this process:
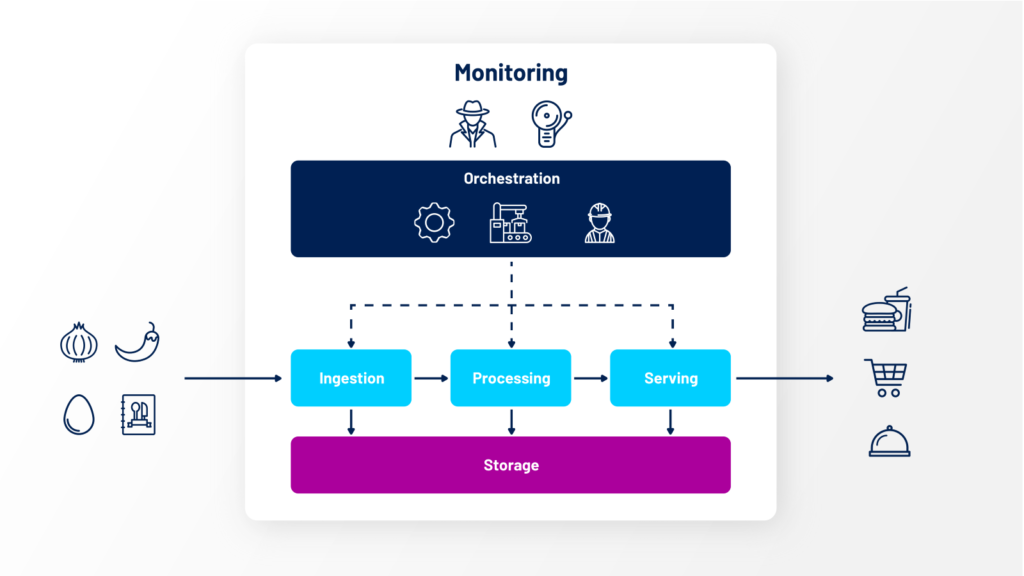
Step 1: Ingestion
In our soup factory, raw materials such as vegetables, herbs and cream are collected in the arrival docks. These raw materials can come from different suppliers, such as local farmers, distributors, and overseas partners. It goes without saying that much of the complexity is caused by the variety of suppliers and the different processes and delivery methods they use.
Today, we observe many of our clients struggling with data coming in from different sources, at different speeds and of different quality levels. In this step, it is common to store resources first, before consuming them in later stages. In the data world, this collection of resources is called a data lake. And it stores all kinds of different data, such as structured data coming from databases, semi-structured data like JSON files and unstructured data like images or videos. Generally, very minimal processing is done at this stage.
Step 2: Processing
Once we have gathered our ingredients, we can start preparing our soup. This can be done in several steps. For example, we first check that our ingredients have not expired. Then we prepare some of the ingredients by chopping or grinding them. And finally, we add them together to cook our soup in large quantities. It is also possible that processed ingredients (e.g. chicken stock) are temporarily stored again before the soup is cooked.
In a data pipeline, we need to identify different steps to clean, transform and combine the data. Outputs from different steps may also be stored in intermediate data stores, resulting in multiple levels of data between the data lake and a potential warehouse.
Step 3: Serving
Once our soup is ready, it is time to get it ready for distribution. As you can imagine, there are more distribution options than just a tank truck. Instead, we usually package our soup in different ways, depending on customer requirements and preferences. For example, a cafeteria might ask for soup to be delivered in large 20L containers, while high-end shops prefer to sell soup in deluxe 0.5L containers.
In the data world, a data warehouse can help by storing cleansed and transformed data that can be queried by BI tools or AI workflows. The data warehouse is structured so that multiple usage patterns can be processed efficiently. At the same time, chefs may want to access raw ingredients and/or slightly processed ingredients to create new recipes, just as a Data Scientist would do with data during an exploratory data analysis.
In addition to these three processing steps, there are three other technical blocks that will help stitch everything together:
Storage
As mentioned, we need a method of storing our ingredients (raw and processed) and our finished products. This can be any kind of storage, depending on the type of product. E.g. cold storage, liquid storage or bulk storage.
In data, we can also distinguish different types of storage solutions, depending on the type of data. E.g. data lakes for unstructured data, and data warehouses for processed data ready to be served to BI-tools.
Orchestration
Our factory would not work effectively without proper orchestration. Raw materials and intermediate resources must flow through our factory in a strict order and on time to make soup. You don’t want to check the expiry date of your ingredients after you have used them to cook your soup, do you?
The same should happen with data. An orchestrator ensures that data pipelines are triggered at the right time. It also makes sure that all dependencies are met before tasks can start, and that tasks happen in the right order.
Monitoring
Throughout the process (not just at the beginning), someone is in charge of ingredient and flavour control. The factory also has smoke detectors and fire alarms ready in case things go wrong. And IF something does go wrong, the right people are alerted.
In a data pipeline, there are similar mechanisms to control the orchestration and the results of the transformations. If a data pipeline fails, a data engineer can be alerted to find the problem and fix it if possible. Automated data quality checks can filter out non-compliant data, and possibly keep them separate for later inspection.
Let’s cook together
Did our soup story inspire you to discuss how we can take the next step in your organisation? Contact us and we will open our kitchen to share our favourite recipes. (Of course, building a new data warehouse is just one concrete application of what we call Data Foundations)
We would love to help you take the next step to becoming The Intelligent Data-Driven Organisation!
My gratitude goes to Bernd Schrooten and Nicolás Morandi for the great discussions, brainstorms and draft versions that lead us to this introductory article. Are remaining errors are my own.
