
Teach the machines
Welcome to the second part of our series about recommender systems. In the first part, we defined the project, how the offer is going to look, and what data we are using. You can find that here. Now it is time to teach the machines!
This article discusses recommender systems and the different approaches used to estimate similarity between users and items. We touch upon well-known concepts such as content-based and interaction-based models, including collaborative filtering and hybrid models. The article also touches on the evaluation of recommender systems, including the challenges posed by sparse data and the importance of sanity checks. We conclude by mentioning the importance of tailoring the approach to specific needs and situations, and by sharing some of our experiences in building recommender systems. Let’s dive in!
“Why do we need to estimate similarity?”
We usually define two general approaches – interaction-based and content based. While interaction-based derives similarity from behavior, content-based focuses on the properties of users or items to calculate similarity. Why do we need to estimate similarity? Good question! If we know that Geert is similar to Wouter, Anthony, and Matthias, we can extract items that those three purchased and Geert did not. That would be an acquire-sell, for example.
Starting with content-based, we have models based on item similarity. Let’s say bacon and smoked ham are fairly similar. If you liked bacon, you will probably like smoked ham as well. Building on that, the second approach is to employ user-similarity models. The assumption is that if two users are similar, based on age, location, or haircut, they will have similar tastes.
The second group of models is based on user or item interactions, sometimes known as collaborative filtering. In the first version, we can build the models on user interactions. If two users purchase the same items, we claim that they are similar (but they can be very different in terms of age or haircut!). Secondly, the item-interaction approach inspects which items have been purchased together. The items might be very different, purchased by various users, yet they are in the same shopping basket, therefore they probably share some, maybe unseen, similarity. The beer-and-diaper urban legend [1] is probably the most famous example. The approaches are visualized below:
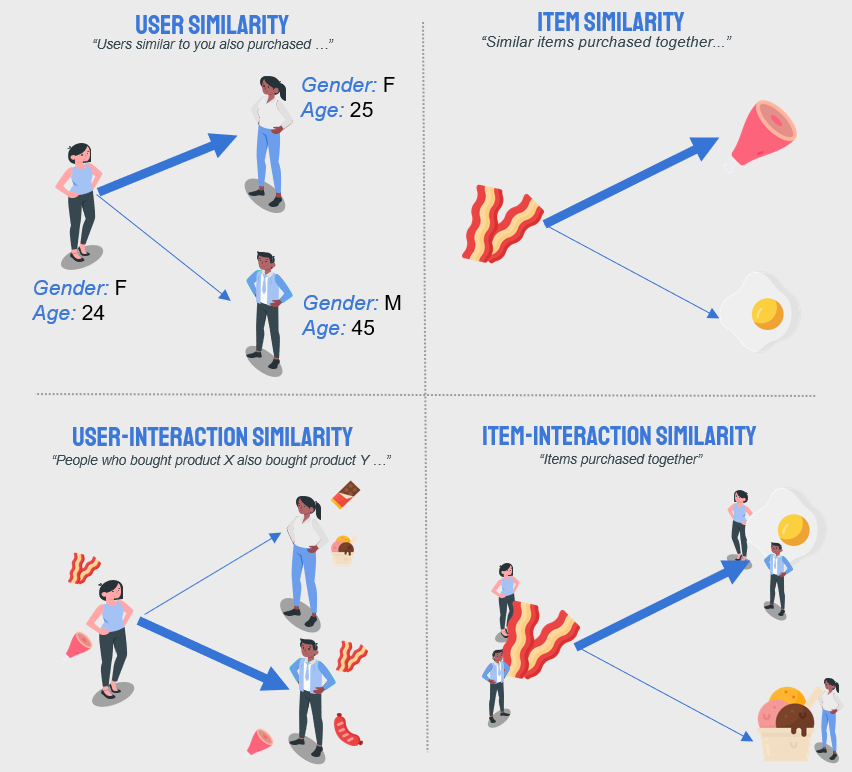
Having mentioned the traditional approaches, there are more esoteric and complex models. Sometimes what works is to combine for example an item- and -user similarity to produce a prediction – we call those hybrid models. Matrix factorization (MF) is another popular algorithm, which helps uncover latent dimensions and recommends relevant items. We can go even further. Keeping up with current research and always experimenting is part of our DNA. We implemented a recent paper [2], suggesting combining MF and clustering to obtain more relevant predictions. Another area of successful models stems from word2vec-like neural networks, which create embeddings [3]. Once we have our data embedded in vectors, calculating similarity is easy not only between users or items but also between user-item pairs.
We always build the models from scratch, tailoring the approach to the exact needs of our customers. Nevertheless, this article would not be complete without mentioning packaged ready-made Python libraries for recommender systems such as SurpriseMe [4] or LightFM [5]. While those can save you some time, they tend to be too generic and/or black-box.
One overlooked aspect when choosing a model is whether it has to be retrained when new data appear. For example, when adding a new user to user-similarity models, we just take the new individual and estimate similarity to the rest. Done. But in cases where we use MF, when adding new users, we need to re-estimate the latent dimensions. In other words, retrain the models. Again, the decision depends on specific needs and situations.
Teaching would not be complete without one crucial aspect which every student needs – evaluation. How do we evaluate recommender systems? The catch is that there is not always a clear ground truth, like with regular classification problems. Imagine we want to evaluate predictions of items never bought before. The goal of these systems is often to suggest products or services that a user may be interested in but has not yet tried or considered. In the case of cross-selling products, again, there is no clear-cut comparison by definition. Two workarounds come to mind. First, splitting the data timewise – take a snapshot and observe who naturally bought the new product in the next number of months. Second, randomly split the data into train and test sets and observe if the model can fill in the gaps correctly. Or, and that’s my favorite approach, dodge this by predicting a category, instead of an item. More on that later.
Once we have our test and prediction sets, we can calculate any measure of our liking. However, we will usually deal with extremely sparse data, therefore when picking an evaluation measure, make sure it takes sparsity into account. Remember, a model accuracy of 99% looks cool but does not tell you anything if the target is very imbalanced. If ranking is important, we can penalize the prediction by how far it is from the correct position. The further the score, the bigger the mistake.
I am always a fan of plain-simple sanity checks. Just looking at a few customers – comparing real and predicted purchases gives a lot of insights into the model behavior. Do the recommendations make sense, given the user history? Are those diverse enough? Does it work for customers with normal and specific behavior?
That’s all for today. In the next, and last, part, we will share some of our experiences with building such systems.
Sources
- [1] https://bigdatabigworld.wordpress.com/2014/11/25/beer-and-nappies/
- [2] https://dl.acm.org/doi/abs/10.1145/3219819.3220112
- [3] https://towardsdatascience.com/building-a-recommendation-system-using-neural-network-embeddings-1ef92e5c80c9
- [4] http://surpriselib.com/
- [5] https://github.com/Gousto/gousto-lightfm
- Approaches visualized: made by the author, icons from www.flaticon.com
