
Efficiently retrieving textual information from large datasets is no easy feat. However, large language models (LLMs) provide a game-changing alternative to traditional methods for retrieving texts. In this article, we will discuss the LLM-based tools for text retrieval that we have built at Python Predictions and the value they provide to businesses.
Unlocking productivity through LLMs
According to a McKinsey report, employees spend 19% of an average workweek searching and gathering information. To reduce the large amount of time spent on information retrieval, we used LLMs to create custom-built chatbots. In the following sections, we describe two use cases that show how chatbots can significantly enhance productivity by introducing a shift from searching for information to directly interacting with it.

Elevating Sustainability Insights with LLMs
For businesses striving towards sustainability, understanding the vast landscape of ESG regulations and documents is vital. However, the sheer volume of ESG-related information, often stretching into thousands of pages, combined with the dynamic nature of regulations, calls for a solution beyond traditional search methods.
Our ESG tool is a custom chatbot that we built on top of OpenAI’s powerful GPT3 language model, making it a top-notch assistant for all things ESG. It’s like having an expert at your fingertips: you ask anything about ESG, and it digs through tons of documents to give you a straight-up, easy-to-get answer. It completely removes the need for sifting through endless documents.
When prompted with a question, the chatbot sifts through the extensive repository of ESG regulatory texts. It doesn’t just search for keywords but understands the context of the question, ensuring that the passages it selects are the most informative with respect to the user’s query.
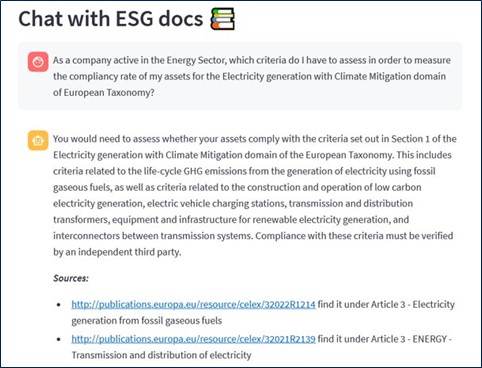
This approach isn’t just for ESG; it can transform many fields where you need quick answers from lots of documents, like insurance and law. We have, for example, created a similar chatbot for our internal knowledge stored on our wiki. If employees need help with company guidelines or their onboarding process, this chatbot efficiently provides them with the necessary information, eliminating the need for exhaustive searches.
Scraping
Web scraping is a great method for extracting information available on the internet. However while scraping one website is feasible, traditional methods often fall short when it comes to scraping hundreds.
For each website, you would need to instruct your scraper on where to locate the information you’re looking for. In addition, whenever a website’s structure changes, your web scraper will fail. Adapting instructions becomes a frequent maintenance task, requiring significant effort. Or, at least, that was the scenario until LLMs entered the scene.
What we’ve built now changes the game. We first download the full HTML source code of the websites we want to scrape, which we then feed to our tool. Next, we let the model navigate through this HTML content to extract the data we need. It’s a more intelligent, autonomous system that significantly streamlines our data collection process.
Let’s dive deeper into two examples that illustrate the value of our new web scraping tool:
Market Analysis Simplified
In one instance, we analyzed competitor data by scraping data from multiple websites in the insurance industry. LLMs showcased their efficiency by rapidly processing and extracting valuable information, providing users with a competitive advantage in the market, a task that traditionally required weeks of development and significant ongoing maintenance.
Crunching Numbers: Language Models Analyze Price Sheets
Another application involved the analysis of price sheets stored in PDF documents. In the past, dealing with such unstructured documents required manual analysis of the PDF markdown to identify and specify the location of relevant information for a scraper. Now, we can prompt an LLM to autonomously locate specific elements within these PDFs, streamlining the extraction process significantly. In summary, what we have built illustrates how LLMs offer immense value by enabling businesses to efficiently extract, structure, and interact with valuable information from unstructured sources. You can simply ask a question and our tool will then fetch the necessary information for you.
If this approach resonates with your needs, our team at Python Predictions is ready to help you implement these solutions effectively. Check out our offer for more information here and give us a call if you’d like to sit down with us and explore your options.
